PrecisionFDA
Truth Challenge
Engage and improve DNA test results with our community challenges
Challenge Time Period
April 26, 2016 through May 26, 2016
At a glance
In the context of whole human genome sequencing, software pipelines typically rely on mapping sequencing reads to a reference genome and subsequently identifying variants (differences). One way of assessing the performance of such pipelines is by using well-characterized datasets such as Genome in a Bottle’s NA12878, also known as HG001. However, we have been hearing from the community that HG001 has been widely used to train software pipelines, and that testing of pipelines would ideally be done on some other sample — perhaps one whose truth data is not provided at the time of testing.
The Genome in a Bottle (GiaB) consortium, lead by the National Institute of Standards (NIST), will be soon releasing a second reference sample, known as HG002, corresponding to their characterization of NA24385 (the son of an Ashkenazim trio).
The FDA has taken this unique opportunity, before the release of the HG002 truth data by GiaB, to set up the second precisionFDA challenge. By supplying sequencing reads datasets (FASTQ) for both HG001 and HG002, and a framework for comparing variant call format (VCF) results, this challenge provides a common frame of reference for measuring performance aspects of participants’ pipelines on both known (HG001) and not-yet-revealed (HG002) truth datasets.
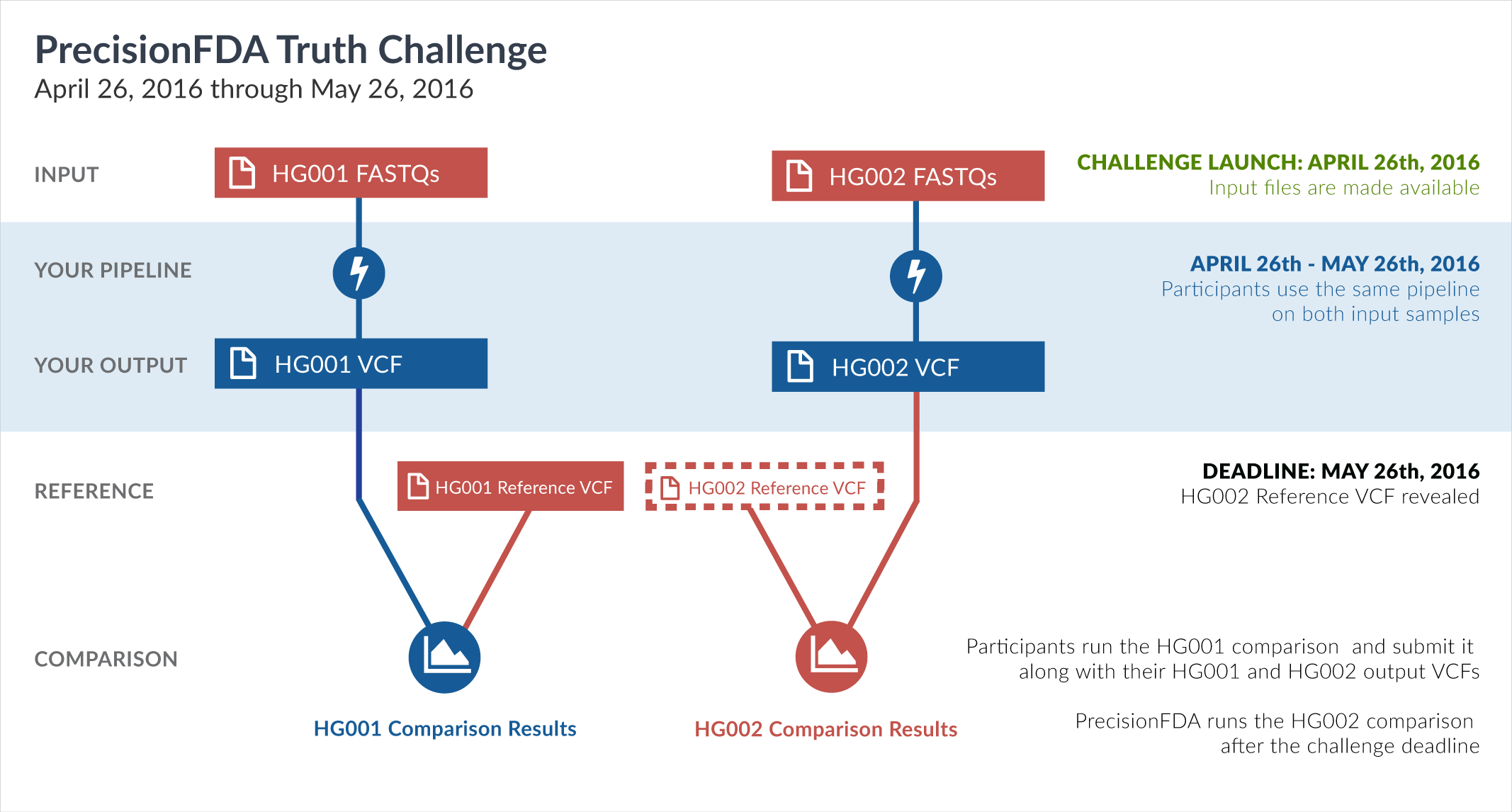
The challenge begins with two precisionFDA-provided input datasets, corresponding to whole-genome sequencing of the HG001 (NA12878) and HG002 (NA24385) human samples. Both samples were sequenced under similar sequencing conditions and instruments, at the same sequencing site. Your mission is to process these two FASTQ datasets through your mapping and variation calling pipeline and create VCF files. You can generate those results on your own environment, and upload them to precisionFDA, or you can reconstruct your pipeline on precisionFDA and run it there. Regardless of how you generate your VCF files, you will subsequently submit them as your entry to the challenge.
For HG002, the truth data will not be known during the challenge. After submissions close on May 26, GiaB will publish their reference VCF file for HG002. The precisionFDA team will then run and publish comparisons between each contestant’s HG002 VCF file and the GiaB HG002 reference VCF. This will publicly reveal how similar is each result to the GiaB HG002 reference.
For HG001, the reference VCF is already available. You are therefore asked to conduct a comparison between your VCF and the GiaB HG001 (NA12878) reference VCF, and include it in your submission entry, for the following reasons:
- to ensure that your VCF files are compatible with the comparison process (remember that we won’t be able to check on your HG002 VCF until after the end of submissions, so you are using your HG001 VCF as a check that your files can be compared without issues)
- for the community to be able to contrast your performance on a previously known sample (HG001) versus a previously unknown (HG002), and to evaluate any overfitting on HG001
Your entry to the challenge comprises your submitted HG001 and HG002 VCFs, your submitted HG001 comparison, and the HG002 comparison conducted by precisionFDA. Each comparison outputs several metrics (such as precision*, recall*, f-measure, or number of common variants). Selected participants and winners** will be recognized on the precisionFDA website. Therefore, we hope you are willing to share your experience with others to further enhance the community's effort to ensure accuracy and truth of tests.
The challenge runs until May 26, 2016.
Challenge details
Last updated: April 26th, 2016
If you do not yet have a contributor account on precisionFDA, file an access request with your complete information, and indicate that you are entering the challenge. The FDA acts as steward to providing the precisionFDA service to the community and ensuring proper use of the resources, so your request will be initially pending. In the meantime, you will receive an email with a link to access the precisionFDA website in browse (guest) mode. Once approved, you will receive another email with your contributor account information.
With your contributor account you can use the features required to participate in the challenge (such as transfer files or run comparisons). Everything you do on precisionFDA is initially private to you (not accessible to the FDA or the rest of the community) until you choose to publicize it. So you can immediately start working on the challenge in private, and whenever you are ready you can officially publish your results as your challenge entry.
The starting point for this challenge consists of two datasets, corresponding to whole-genome sequencing of the HG001 (NA12878) and HG002 (NA24385) samples on an Illumina HiSeq 2500 instrument at a single site. A pair of gzipped FASTQ files is provided for each dataset. The following table summarizes key information for each dataset:
| Dataset | HG001 | HG002 |
|---|---|---|
| Files |
HG001-NA12878-50x_1.fastq.gz
HG001-NA12878-50x_2.fastq.gz |
HG002-NA24385-50x_1.fastq.gz
HG002-NA24385-50x_2.fastq.gz |
| Sequencing Site | NIST, Gaithersburg, MD | |
| Library Prep | Illumina TruSeq (LT) DNA PCR-Free Sample Prep Kits (FC-121-3001), multiplexing 12-14 libraries from the same genome | |
| Read Length | 2x148bp | |
| Insert Size | ~550bp | |
| Instrument and Sequencing Chemistry | HiSeq 2500 Rapid Mode v1 (2 flow cells per genome) | |
| Approximate Coverage | 50x | 50x |
We would like to thank the Genome in a Bottle consortium for contributing these files.
In the next step you will need to process these FASTQ files through your pipeline to generate VCF files. This can be done either by downloading the files and running your pipeline on your own environment, or by reconstructing your pipeline on precisionFDA and running it there. If you will be working on your own environment, download these datasets by visiting the links above and clicking the Download button (web-browser download, not recommended for large files) or the Authorized URL button.
After familiarizing yourself with the input files, you will need to process them through your mapping and variation calling pipeline to generate corresponding VCF files. Your pipeline must call variants across the whole genome. Each invocation of your pipeline must take as input a pair of FASTQ files and produce a VCF file containing exactly one genotyped sample. Results must be reported on GRCh37 human coordinates (i.e. chromosomes named 1, 2, ..., X, Y, and MT). You are strongly encouraged to compress each VCF file with bgzip, to reduce the file size.
| DO | DON'T |
|---|---|
|
Use GRCh37 Call variants across the whole genome Compress with bgzip |
Use hg19 or GRCh38 Call variants only in specific regions Generate a gVCF |
You will need to invoke your pipeline once on the HG001 pair of FASTQ files to obtain your HG001 VCF, and once on the HG002 pair of FASTQ files to obtain your HG002 VCF.
| Invocation | Input dataset (FASTQ pair) | Output dataset | Example output filename |
|---|---|---|---|
| #1 | HG001 | HG001 VCF | YourName-HG001.vcf.gz |
| #2 | HG002 | HG002 VCF | YourName-HG002.vcf.gz |
The input files for this challenge correspond to 50x coverage, hence are larger than the ones used in the first precisionFDA challenge. If you previously participated in the first challenge, make sure your pipeline can handle the increased input size.
If you are running your pipeline in your own environment, upload the two generated files to precisionFDA. Additional information on uploading files is available at the precisionFDA docs. Your uploaded files are private, until you are ready to share them with the community (see "Submitting your entry" below).
Besides running your pipeline in your own environment, you have the additional option of reconstructing your pipeline on precisionFDA and running it there. To do that, you must create one or more apps on precisionFDA that encapsulate the actions performed in your pipeline. To create an app, you can provide Linux executables and an accompanying shell script to be run inside an Ubuntu VM on the cloud. The precisionFDA website contains extensive documentation on how to create apps, and you can also click the Fork button on an existing app (such as bwa_mem_bamsormadup) to use it as starting point for developing your own.
Constructing your pipeline on precisionFDA has an important advantage: you can, at your discretion, share it with the community, so that others can take a look at it and reproduce your results – and perhaps build upon it and further improve it.
Regardless of how you generate your VCFs (whether in your own environment or directly on precisionFDA), they will be compared to the respective GiaB reference VCFs. As mentioned in the introduction, the HG001 comparison needs to be conducted by you, as a check that your files are compatible with the comparison framework, and for the community to evaluate aspects of your pipeline’s performance (and potential overfitness) on known samples. The HG002 comparison will be conducted by the precisionFDA team after the submission deadline.
The precisionFDA comparison framework makes use of vcfeval by Real Time Genomics (Cleary et al., 2015) to perform a pairwise comparison between a test VCF and a benchmark VCF, optionally constrained within certain coordinates provided by BED files (a test BED and a benchmark BED). For more information consult the precisionFDA docs. The following table summarizes the comparisons (you will only conduct the first one yourself):
| Comparison | Conducted by | Test VCF | Test BED | Benchmark VCF | Benchmark BED |
|---|---|---|---|---|---|
| HG001 | You | Your HG001 VCF | - | NIST v2.19 VCF | NIST v2.19 BED |
| HG002 | precisionFDA | Your HG002 VCF | - | (revealed after May 26) | (revealed after May 26) |
The HG001 comparison is between your HG001 VCF and the NIST/GiaB v2.19 benchmark VCF file for the same sample, constrained within the coordinates of the accompanying GiaB v2.19 BED file. The precisionFDA website provides NA12878-NISTv2.19.vcf.gz (to be used as benchmark VCF) and NA12878-NISTv2.19.bed (to be used as benchmark BED). This comparison is meant to estimate the accuracy of your pipeline within the “confident” regions of the Genome in a Bottle HG001 truth dataset — therefore you must leave the test BED entry blank.
Your comparison is private, until you are ready to share it with the community (see "Submitting your entry" below).
To ensure that you are on the right track, your HG001 comparison must meet a precision* and recall* threshold of at least 90%.
This challenge has been posted to the precisionFDA “Discussions” section. Discussion answers can include rich text formatting, as well as attachments such as files or comparisons. You can leverage this functionality to submit your entry by filling in your answer to the question.
In your answer’s text, please identify whether you are participating as an individual or as part of the team (and, if it is a team effort, don’t forget to identify the members of your team). Write a description of the pipeline used to obtain the results, and identify the name, version and command-line parameters of the mapper and variant caller invoked in your pipeline.
If you opted to construct your pipeline on precisionFDA, and your VCFs were generated by running one or more precisionFDA apps, the system will automatically prompt you to share the details of these executions when publishing your answer (see below). In that case, your text only needs to provide a high-level summary, because the exact software invocations will be available to the community via the system’s sharing mechanism.
Once you save your answer, it is initially private (and only visible to you). You can go back at any point and edit it, so we encourage you to start drafting it right away, and revise it as you make progress. Once you instantiate your answer, you can attach your VCFs and your HG001 comparison to it by visiting each item and clicking Attach, and selecting your answer. Your entry must contain two VCF files (one for HG001 and one for HG002) and the HG001 comparison (as outlined in the previous section) in order to be considered valid.
Once you are comfortable with your answer, you can publish it so that others can see it (and don’t worry – you can still edit it or update its attachments even after publication). When publishing, the system will ask if you want to publish the comparisons, as well as the VCF files that were input to the comparisons; please choose that option to ensure that these artifacts are shared with the precisionFDA community. Entries that do not have their comparisons and VCF files published will not be considered valid. If you used apps on precisionFDA (instead of generating these VCF files externally), please choose the option to share the underlying jobs, apps, and app assets.
All valid submitted entries, after vetted by precisionFDA, and after meeting minimum criteria for performance on HG002, will receive an acknowledgement for participation in the challenge. Among these entries, the precisionFDA team will select a few winners** to be recognized on the precisionFDA website. Winning criteria may include, but are not limited to, comparison metrics on HG002 (such as precision*, recall*, f-measure). For more information about the metrics output by the comparison, consult the precisionFDA docs.
Footnotes
* The terminology currently used in the precisionFDA comparison output (such as "precision" and "recall") is not necessarily harmonized with definitions used by ISO, CLSI, or FDA, but are terms commonly used by NGS software developers.
** Winning a precisionFDA challenge is an acknowledgement by the precisionFDA community and does not imply FDA endorsement of any organization, tool, software, etc.